顿搜
飞过闲红千叶,夕岸在哪
类目归类
顿搜
执行如下代码开启Hadoop。(注:我是因为已经配置了PATH,所以所有命令前面的bin/都省略了)
start-dfs.sh
start-yarn.sh伪分布式读取的是 HDFS 上的数据。要使用 HDFS,首先需要创建用户目录。
执行以下命令,创建用户目录。
hdfs dfs -mkdir -p /user/hadoop![]()
将/etc/hadoop/中的文件作为输入文件复制到分布式文件系统中。即将/opt/software/hadoop-2.7.1/etc/hadoop复制到分布式文件系统中的/user/hadoop/input中。目录/user/hadoop/已经在上一步创建好了。因此命令中就可以使用相对目录如 input,其对应的绝对路径就是 /user/hadoop/input
执行以下命令
hdfs dfs -mkdir input #常见input目录
#将输入文件拷贝到input目录中
hdfs dfs -put /opt/software/hadoop-2.7.1/etc/hadoop/*.xml input
hdfs dfs -ls input #查看拷贝的文件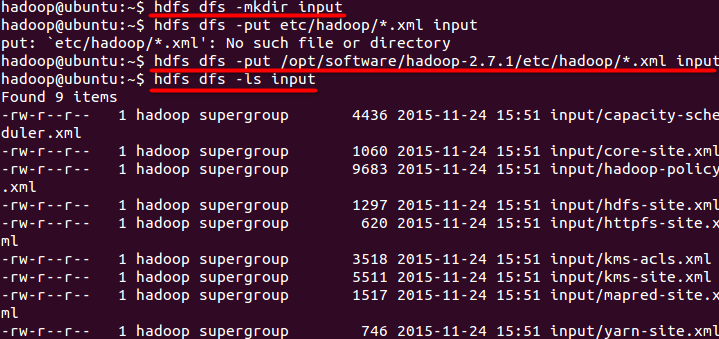
现在我们可以执行Hadoop例子了。Hadoop 附带了丰富的例子(运行 bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar 可以看到所有例子),包括 wordcount、terasort、join、grep 等。
此处我们选择运行 grep 例子,即将 input 文件夹中的所有文件作为输入,筛选当中符合正则表达式 dfs[a-z.]+ 的单词并统计出现的次数,最后输出结果到 output 文件夹中。
输入以下命令执行
hadoop jar /opt/software/hadoop-2.7.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep input output 'dfs[a-z.]+'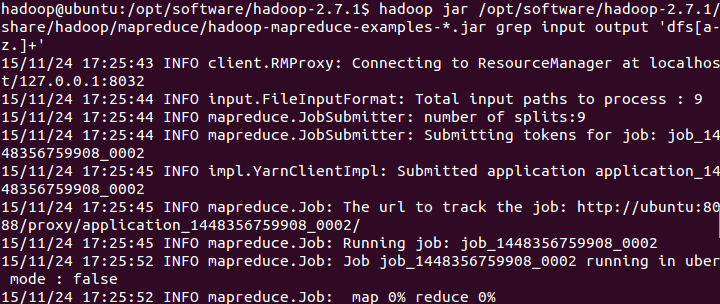
可以看到Map和Reduce的过程
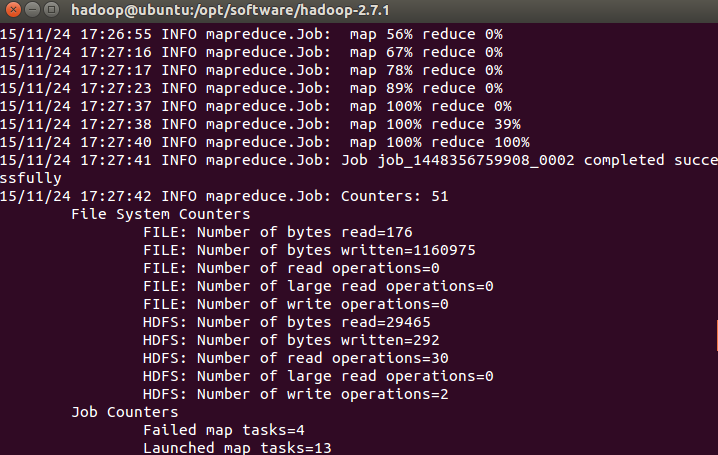
输入以下命令查看运行结果(查看的是位于 HDFS 中的输出结果)
hdfs dfs -cat /user/hadoop/output/*
Hadoop运行程序时,默认输出目录不能存在,因此再次运行需要执行如下命令删除 output文件夹
hdfs dfs -rm -r /user/hadoop/output
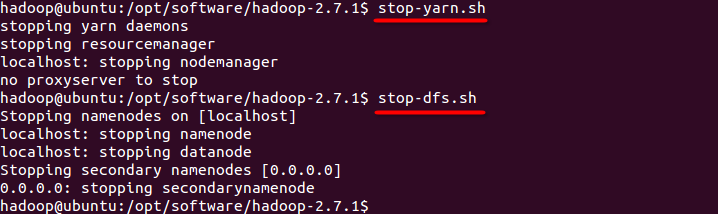
如果要关闭hadoop,执行如下命令
stop-yarn.sh
stop-dfs.sh