HDFS是Hadoop的分布式文件系统。
一、设计原理
设计HDFS考虑的五个因素:
- 硬件故障是常态而非偶然因素(最核心的目标)
- HDFS适用于批处理的数据处理场景,采用高效的流式访问。
- 计算节点容易扩充,把运算能力赋予数据单元
- 简单的数据一致性模型(一次写入多次读出的访问模型)
- 异构平台可移植性。
二、基本概念
以下是四个基本概念:
- 机架:HDFS集群由分部在大量机架上的DataNode组成。
- 数据块:是HDFS最基本的存储单元。默认的数据块大小是64M(Hadoop为128M)。
- 元数据:是文件和目录的属性信息。采用了镜像文件(Fsimage)+日志文件(Editlog)的机制
- 用户数据:以数据块的形式存储在DataNode上。
三、节点通信
不同机架节点间通过交换机通信(TCP协议)。HDFS通过机架感知策略使NameNode能够确定每个DataNode所属的机架ID。使用副本存放策略,改进数据的可靠性、可用性和网络带宽的利用率。
通过心跳机制DataNode向NameNode报告自己仍然存活。每十次心跳后,向NameNode发送一次数据块报告,告诉自己存储的数据块信息。通过这些信息,NameNode能够重建元数据,并确保每个数据块有足够的副本
四、写数据流程
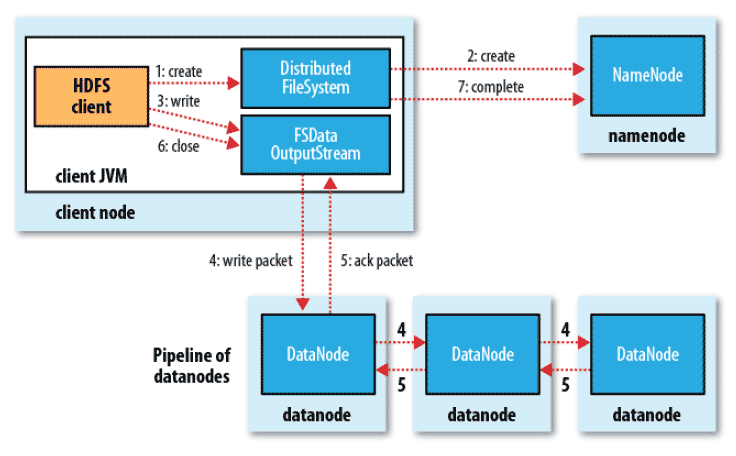
步骤:
- 客户端通过Open函数打开分布式文件系统
- 分布式文件系统通过远程过程调用访问NameNode,在文件系统中创建一个新的文件。
- 客户端通过文件系统输出流开始写入数据
- 文件系统输出流将文件分成块写入数据队列,DataStream负责处理队列,
- 将数据块写入一个DataNode,然后这个DataNode将数据块发送给另一个DataNode。。。
- 数据写完后,文件系统输出流将受到确认包。
- 调用Close函数,关闭写入流,标志本次写入完毕。
五、读数据流程
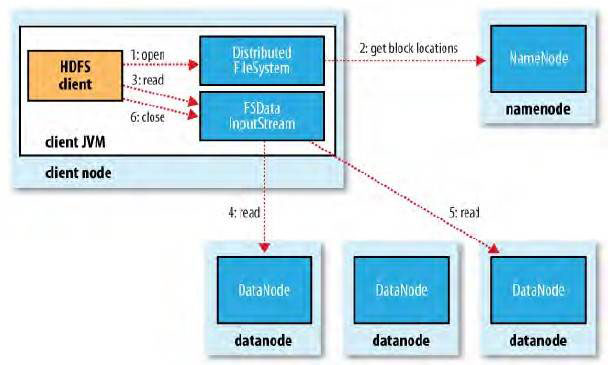
步骤:
- 客户端调用Open函数打开文件
- 分布式文件系统通过远程过程调用访问NameNode,得到文件的数据块信息
- 客户端调用文件系统输入流开始读入数据
- 文件系统输入流根据相应策略向DataNode发起连接。
- 建立了连接的DataNode向客户端返回相应的数据块内容。
- 当本DataNode数据读完后,关闭连接并向下一个DataNode发送连接请求。
- 当请求的数据块都读取后,关闭文件系统输入流。
- 当读取出错,就会向副本发出连接请求,并记录错误的DataNode,报告给NameNode。




