
顿搜
飞过闲红千叶,夕岸在哪
类目归类
顿搜
MapReduce是一种分布式编程架构。致力于解决大规模数据处理的问题。
它以数据为中心,数据的吞吐率决定MapReduce的性能。采用了分而治之的思想,把对大规模级的数据操作分发给一个主节点管理下的各个分节点共同完成,然后通过整合各个节点的中间结果得到最终输出。
MapReduce就是任务的分解和结果的汇总,编程核心是Map和Reduce这两个函数。Map负责任务分解,把一个任务分解成多个子任务。Reduce将分解后的多个子任务分别处理,并将结果汇总为最终结果。
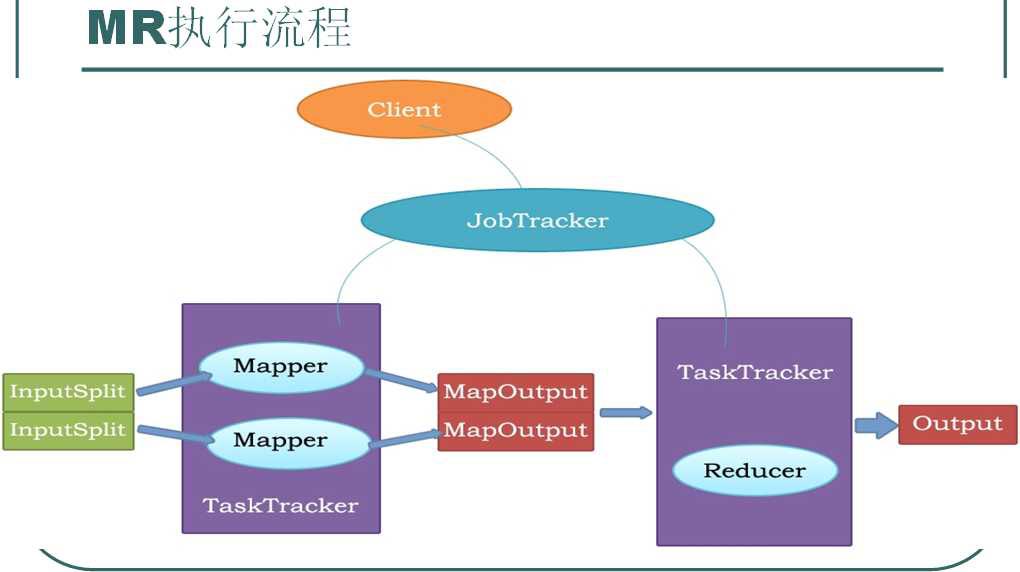
1、用户编写的程序通过客户端提交给JobTracker,同时用户也可以通过Client提供的接口查看作业的运行状态。
2、JobTracker是MapReduce架构的主节点,一个MapReduce只有一个JobTracker,它负责作业的初始化和分配,与任务节点进行通讯,协调整个作业的执行。
3、TaskTracker是MapReduce架构的任务节点。一个作业中可以重载多个TaskTracker。它负责保持与JobTracker的通信。在分配的数据片上执行Map或者Reduce操作。通过TaskTracker的Map运算,得到中间结果。存储在TaskTracker的本地主机上。这些中间结果经过Reduce运算,得到MapReduce的最终结果。
4、HDFS用于存储作业的输入数据,配置信息等以及最终的结果。
一些基本术语:
四个阶段:
注:JobTracker通过计数器来了解整个作业的进度。作业调度算法包括:FIFO调度器、公平调度器、容量调度器。



