
顿搜
飞过闲红千叶,夕岸在哪
类目归类
顿搜
执行以下命令添加hadoop用户
useradd -m hadoop -s /bin/bash执行以下命令设置hadoop的密码
passwd hadoop执行以下命令给hadoop用户添加管理员权限
adduser hadoop sudo执行以下命令更新APT
apt-get update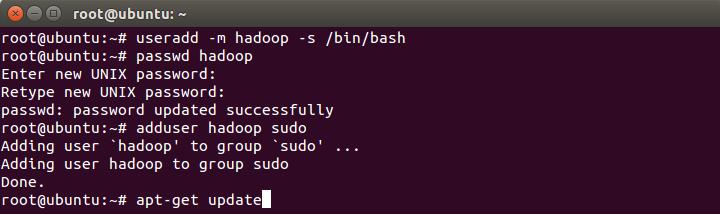
集群、单节点模式都需要用到SSH登陆。
安装过程请参考 Linux Ubuntu 14.04 下安装SSH server、配置SSH无密码登陆
安装过成请参考 Linux Ubuntu 14.04 下JDK 8 的安装与配置
可以直接下载编译好的二进制代码,也可下载源代码自己编译。
相关下载和编译的方法参见 Hadoop编译——Linux Ubuntu 14.04 手动编译Hadoop 2.7.1源码
在/opt/目录下创建software目录
mkdir software将编译好的Hadoop文件拷贝到/opt/software目录下
cp hadoop-2.7.1.tar.gz /opt/software
然后切换到/opt/software目录下,解压hadoop
tar -zvxf hadoop-2.7.1.tar.gz
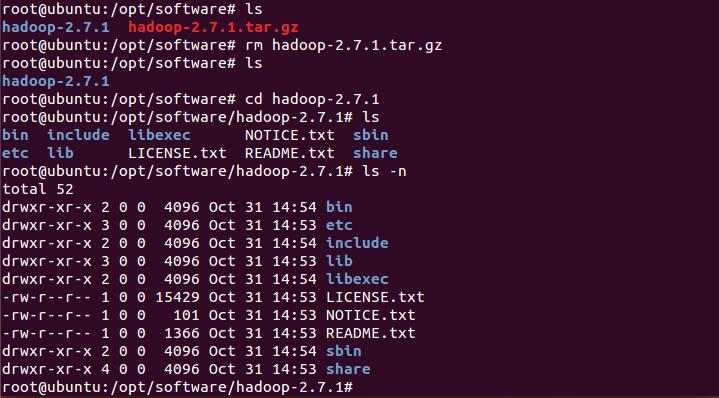
Hadoop 可以在单节点上以伪分布的方式运行,那么Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode。Hadoop 的配置文件位于hadoop-2.7.1/etc/hadoop/中。伪分布式需要修改一些配置文件。
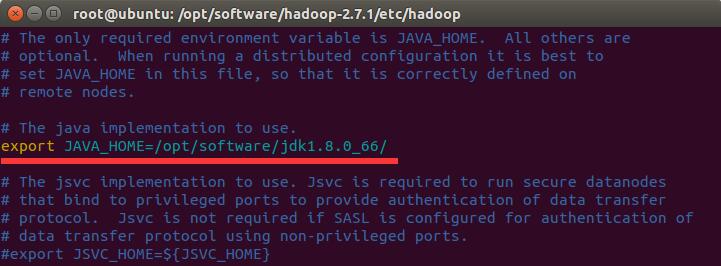
sudo vim hadoop-env.sh然后将JAVA_HOME的值设置为/opt/software/jdk1.8.0_66
sudo vim yarn-env.sh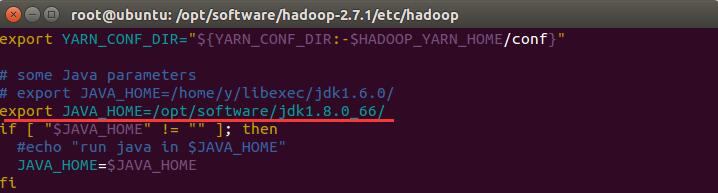
sudo vim mapred-env.sh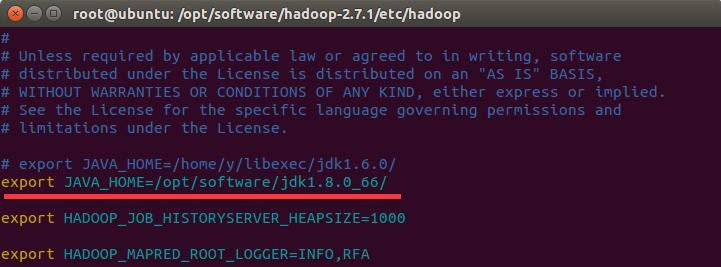
切换到/opt/software/hadoop-2.7.1 ,先创建一个data/tmp文件夹,用户存放临时文件。
sudo mkdir data
cd data
sudo mkdir tmp
cd tmp
sudo mkdir core
sudo mkdir dfs
cd dfs
sudo mkdir name
sudo mkdir data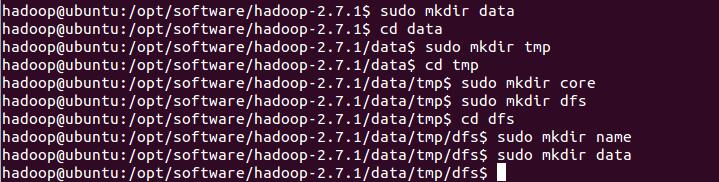
然后切换到/opt/software/hadoop-2.7.1/etc/hadoop目录下,编辑core-site.xml文件
vim core-site.xml增加如下内容
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/software/hadoop-2.7.1/data/tmp/core</value>
<description>Abase for other temporary directories.</description> </property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9090</value>
</property>
</configuration>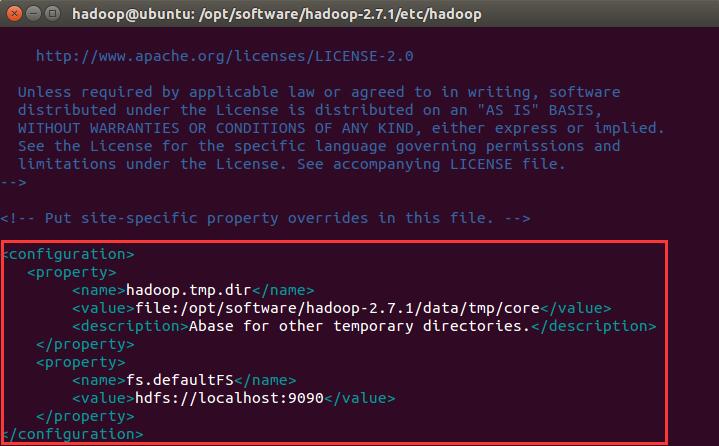
vim hdfs-site.xml增加以下内容
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/software/hadoop-2.7.1/data/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/software/hadoop-2.7.1/data/tmp/dfs/data</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
</configuration>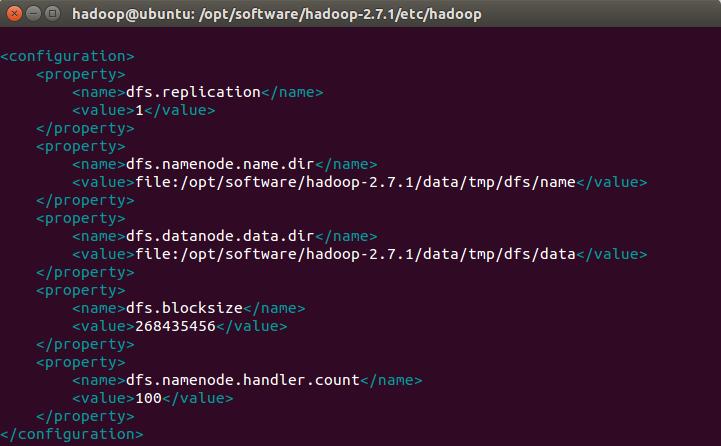
vim yarn-site.xml增加以下内容
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>localhost:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>localhost:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>localhost:8031</value>
</property>
</configuration>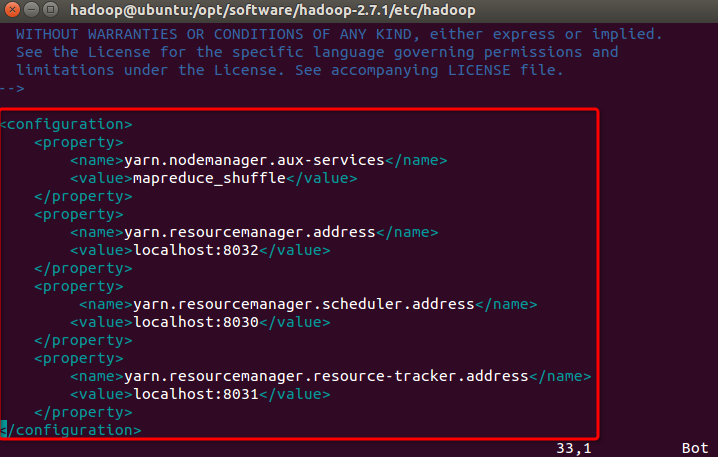
首先将模板拷贝一份,命名为mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
vim mapred-site.xml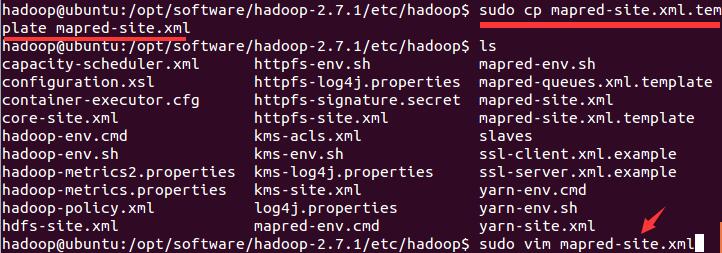
编辑mapred-site.xml文件,增加以下内容
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>1536</value>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx1024M</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>3027</value>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx2560M</value>
</property>
<property>
<name>mapreduce.task.io.sort.mb</name>
<value>512</value>
</property>
<property>
<name>mapreduce.task.io.sort.factor</name>
<value>100</value>
</property>
<property>
<name>mapreduce.reduce.shuffle.parallelcopies</name>
<value>50</value>
</property>
</configuration>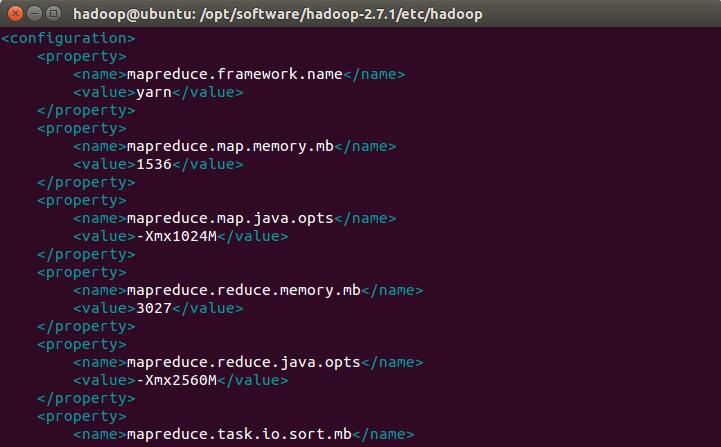
切换到/opt/software/hadoop-2.7.1/ ,首先赋予data目录及子目录权限。
sudo chmod -R 777 data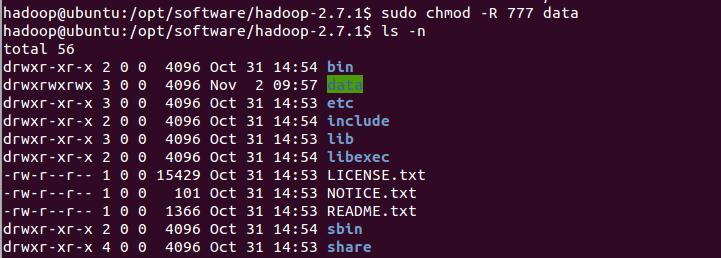
然后进行格式化
bin/hdfs namenode -format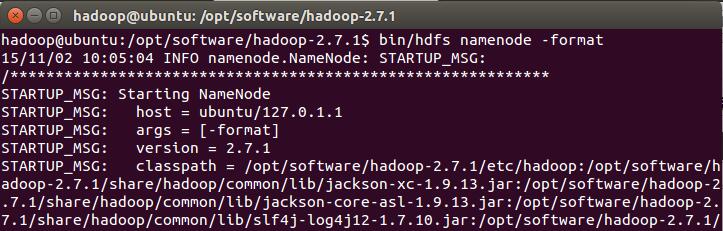
出现以下画面表示格式化成功
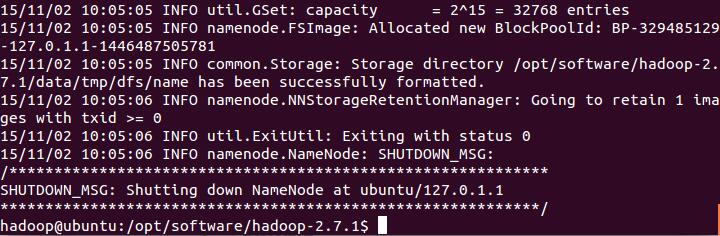
首先创建日志存放目录logs ,并赋予权限。
sudo mkdir logs
chmod -R 777 logs
执行以下命令启动NameNode 和DataNode, 如果屏幕等待输入yes/no,输入yes即可
sbin/start-dfs.sh
可以通过命令jps来检查是否成功启动,若成功,则会列出如下进程:NameNode、DataNode和SecondaryNameNode,若某个进程没有启动,请到logs文件夹中查看失败原因。如我第一次NameNode就没有启动。

查看hadoop-hadoop-namenode-ubuntu.log,发现是下列文件没有权限。

于是切换到相应路径,输入以下命令赋予权限.
sudo chmod -R 777 current
然后使用sbin/stop-dfs.sh停止开启的服务,使用jps检查服务是否已停止,然后使用sbin/start-dfs.sh开启服务,使用jps检查是否成功开启。可以看到,NameNode、DataNode、SecondaryNameNode都已经成功启动了
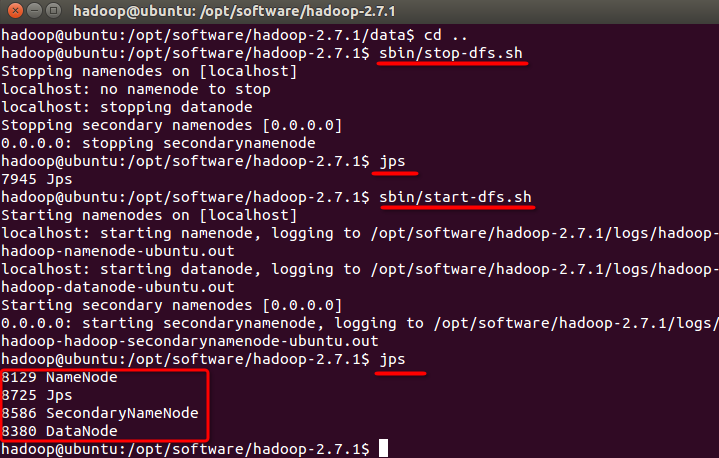
最后在浏览器中输入http://localhost:50070。如下图,可以看到hadoop的信息。
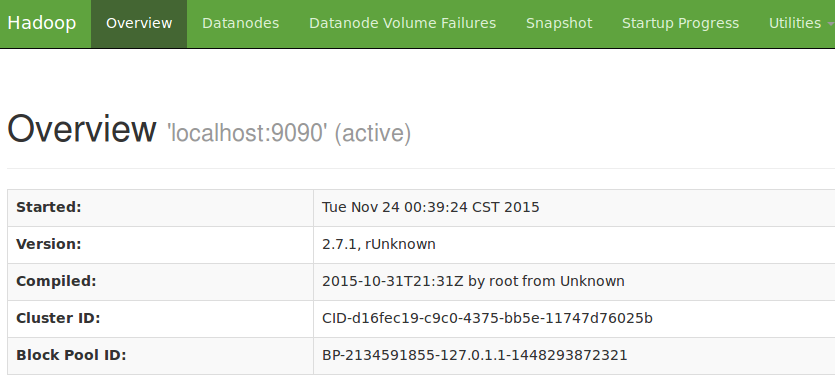
每次启动hadoop都要切换到安装目录,比较麻烦,我们可以通过配置PATH环境变量,在任意的目录下启动通过命令start-dfs.sh来启动hadooop。通过命令stop-dfs.sh来关闭hadoop。也可以直接通过hdfs访问HDFS的内容。
编辑/etc/profile配置文件,讲如下代码加入进去。
export PATH=$PATH:/opt/software/hadoop-2.7.1/sbin:/opt/software/hadoop-2.7.1/bin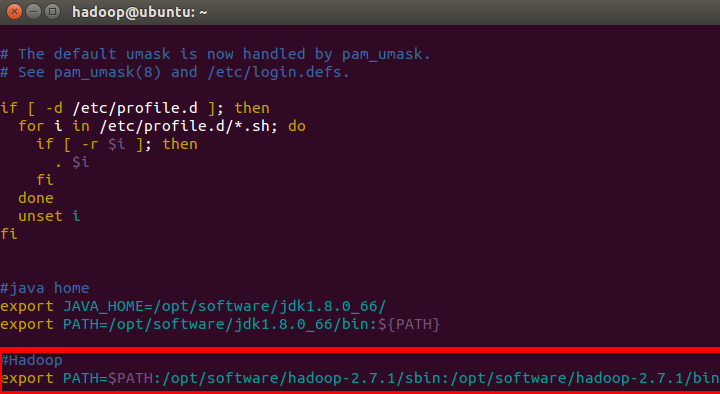
然后执行source /etc/profile 是配置文件生效即可。



